Struct padding in C and C++
Struct padding in C and C++ is a feature that has huge potential in tripping up any kind of program that communicates with another machine. Let’s look at what it means.
Let us define a struct item that contains a single character c and an integer num.
struct item {
char c;
int num;
};As we know, the size of a char is 1 byte, and an int is 4 bytes. Naively, an instance of item should be 5 bytes long. But this is not true.
std::cout << "size=" << sizeof(struct item);Output:
size=8The size is actually 8 bytes. If we print the offset of both individual struct members, it will become clear why.
struct item i;
std::cout << "&i=" << &i << '\n';
std::cout << "&i.c=" << (void *)&i.c << '\n';
std::cout << "&i.num=" << &i.num << '\n';Output:
&i=0x7ffe1fb13c40
&i.c=0x7ffe1fb13c40
&i.num=0x7ffe1fb13c44The object i itself is located at 0x7ffe1fb13c40 in memory. The first member char c is also located at the same address. However, the member int num is located at 0x7ffe1fb13c44 which is 4 bytes ahead of c. The compiler has inserted 3 bytes of padding. Padding is just empty space in memory that will never be used. It is part of the object, so it contributes to the size of the entire object.
This is done by the compiler because most CPUs do not like accessing unaligned data in memory. The rule of thumb about processor memory alignment requirements is that data is aligned when its memory address is a multiple of the size of the data.
So single-byte accesses are always aligned, 4-byte accesses are aligned at addresses 0x0, 0x4, 0x8, 0xc, 0x10 and so on for all multiples of 4 bytes. For an 8-byte data, like a long, these addresses would be multiples of 8.
What happens when you try to access unaligned data? It depends on the CPU architecture. Some CPU families like MIPS or older ARM processors will throw an exception. The current program will be halted and control given back to the OS. The OS can show you an error message and generate a core dump for debugging.
On newer ARP CPUs and Intel/AMD x86/x64 processors, the logic to handle unaligned operations is built into the hardware. The CPU will perform extra operations and the access will still work. This will be slower than aligned memory access. For example, if a 4-byte integer is located at unalogned address 0x1, the CPU will perform two 4-byte memory operations, one at 0x0 and the other at 0x4 and then combine the two reads to construct the integer.
To prevent slowdowns, even on CPUs that support unaligned access, compilers will restructure your data such that each access is aligned. That is what is happening in our example. The compiler has moved our num to the next 4-byte boundary.
What are the problems this can create when you want to communicate with another machine? Let’s say you construct this object and send it over the network. If the recipient of our data is another kind of CPU, it may have diferent anlignement boundaries. Or it may be running code compiled by a compiler that follows a different padding scheme. In that case, our data transfer would fail, values would not be copied to the correct struct members.
To solve this problem, whenever we send data in binary form to another machine (over the network or by writing to a file), the standard practice is to pack the data structure. We tell the compiler not to use any padding bytes to align data members.
struct __attribute__((packed)) item_ul {
char a;
int num;
};Now the memory locations of the members are exactly where we would expect them, and the size of the entire object is 5 bytes.
Output:
sizeof(struct item_ul)=5
&i=0x7ffe1fb13c40
&i.c=0x7ffe1fb13c40
&i.num=0x7ffe1fb13c41The next thing I wanted to know is how much of a performance slowdown does unaligned access cause? This article explains the reasons for padding in great detail. It also shows that unaligned data access can be ~460x slower in MIPS processors.
To replicate these results, I wrote my own little program to copy the ints inside the above structs.
#define ITERATIONS 100000
struct aligned {
char a;
int num;
};
struct __attribute__((packed)) unaligned {
char a;
int num;
};
static void ulcopy(benchmark::State &state) {
struct unaligned *from = new struct unaligned[ITERATIONS];
struct unaligned *to = new struct unaligned[ITERATIONS];
for (int i = 0; i < ITERATIONS; i=i+2) {
from[i].num = i;
}
for (auto _ : state) {
for (int i = 0; i < ITERATIONS; i=i+2) {
to[i].num = from[i].num;
}
}
}
BENCHMARK(ulcopy);
static void alcopy(benchmark::State &state) {
struct aligned *from = new struct aligned[ITERATIONS];
struct aligned *to = new struct aligned[ITERATIONS];
for (int i = 0; i < ITERATIONS; i=i+2) {
from[i].num = i;
}
for (auto _ : state) {
for (int i = 0; i < ITERATIONS; i=i+2) {
to[i].num = from[i].num;
}
}
}
BENCHMARK(alcopy);Here are the results on the excellent QuickBench website.
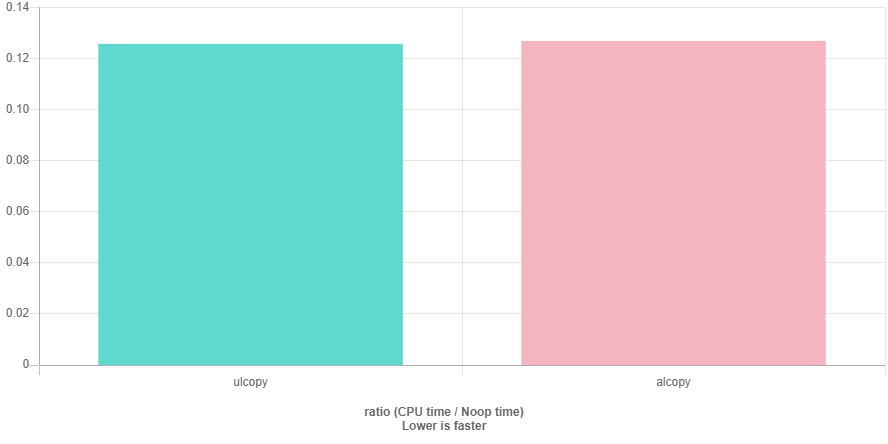
Surprisingly, both are exactly the same speed. In fact, unaligned copy was 0.12566s and aligned copy was 0.12680s. I used a std::vector instead of an array. Same results. I removed the char completely from the aligned struct. Same results.
To conclude, aligned accesses are supposed to be faster than unaligned accesses, but I was unable to reproduce such a result. In the future, I will run this benchmark again on an ARM CPU.